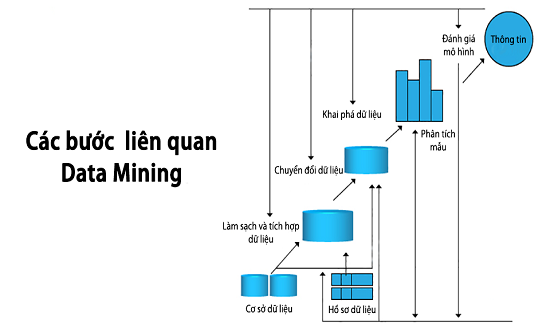
Hiện nay với sự phát triển của công nghệ và thông tin chắc hẳn chúng ta đã hiểu rất rõ về dữ liệu đầu vào và dữ liệu đầu ra. Loại dữ liệu này được ứng dụng vào kinh doanh rất phổ biến. Cùng bài viết tìm hiểu về dữ liệu đầu vào là gì? Dữ liệu đầu vào và dữ liệu đầu ra?
Mục lục bài viết
1. Dữ liệu đầu vào là gì?
Dữ liệu đầu vào được định nghĩa là phần dữ liệu chính, tối cần thiết với các doanh nghiệp và các đơn vị kinh doanh và được sử dụng cho một phần mềm cụ thể, VD: khách hàng, nhà cung cấp, sản phẩm, giá cả, chi phí và dịch vụ. Những loại thông tin được sử dụng làm dữ liệu đầu vào rất đa dạng phụ thuộc vào các ngành, các tổ chức khác nhau cũng như các phần mềm khác nhau. Tuy nhiên, không phải dữ liệu đầu vào chất lượng nào cũng đủ tạo nên một nguồn dữ liệu tốt cho doanh nghiệp. Điều này phụ thuộc vào chất lượng và cách tổ chức quản lý dữ liệu đầu vào của doanh nghiệp.
Phân tích đầu vào – đầu ra trong tiếng Anh là Input-Output Analysis, viết tắt là I-O Analysis.
Phân tích đầu vào – đầu ra là một phương pháp phân tích kinh tế vĩ mô dựa trên sự phụ thuộc lẫn nhau giữa các ngành trong nền kinh tế.
Phương pháp này thường được sử dụng để ước tính tác động của các cú sốc kinh tế tích cực hoặc tiêu cực và phân tích các tác động lan tỏa trong toàn bộ nền kinh tế.
Phương pháp phân tích kinh tế này ban đầu được phát triển bởi Wassily Leontief (1905 – 1999), người đã giành giải Nobel về Kinh tế cho công trình của mình trong lĩnh vực này.
Nền tảng của phân tích đầu vào – đầu ra liên quan đến các bảng đầu vào – đầu ra. Các bảng như vậy bao gồm một loạt các hàng và cột dữ liệu định lượng chuỗi cung ứng cho tất cả các lĩnh vực trong một nền kinh tế.
Các ngành được liệt kê trong dòng tiêu đề của mỗi hàng và mỗi cột. Dữ liệu trong mỗi cột tương ứng với mức đầu vào được sử dụng trong hàm sản xuất của ngành đó.
Ví dụ cụ thể: cột cho sản xuất ô tô liệt kê các tài nguyên cần thiết để chế tạo ô tô (ví dụ: thép, nhôm, nhựa, điện tử, v.v.).
Mặc dù phân tích đầu vào – đầu ra không được sử dụng phổ biến bởi kinh tế học tân cổ điển hoặc bởi các cố vấn chính sách ở phương Tây, chúng được sử dụng trong phân tích kinh tế kế hoạch hóa tập trung.
2. Dữ liệu đầu vào và dữ liệu đầu ra:
Các mô hình đầu vào và mô hình đầu ra xem xét ba loại cụ thể như sau:
2.1. Ba loại tác động kinh tế:
ác động: tác động trực tiếp, tác động gián tiếp và tác động gây ra. Bằng cách sử dụng các mô hình đầu vào – đầu ra các nhà kinh tế có thể ước tính sự thay đổi đầu ra giữa các ngành do sự thay đổi đầu vào của một hoặc nhiều ngành cụ thể.
Tác động trực tiếp của một cú sốc kinh tế là dẫn đến sự thay đổi trong chi phí ban đầu. Ví dụ, xây dựng một cây cầu sẽ tiêu tốn chi phí cho xi măng, thép, thiết bị xây dựng, lao động và các yếu tố đầu vào khác.
Tác động gián tiếp hay tác động thứ yếu được tạo ra do các nhà cung cấp đầu vào thuê nhân công để đáp ứng nhu cầu công việc.
Tác động gây ra hay còn gọi là tác động cấp ba xảy ra do công nhân của các công ty cung cấp mua thêm các hàng hóa và dịch vụ.
Phân tích đầu vào – đầu ra cũng có thể được thực hiện ngược lại, để xác định xem ảnh hưởng nào đến đầu vào là nguyên nhân dẫn đến những thay đổi trong đầu ra.
2.2. Ví dụ về phân tích đầu vào – đầu ra:
Một chính quyền địa phương muốn xây dựng một cây cầu mới và cần phải xác minh chi phí đầu tư. Để làm như vậy, họ thuê một nhà kinh tế để thực hiện một nghiên cứu phân tích đầu vào – đầu ra.
Nhà kinh tế nói chuyện với các kĩ sư và công ty xây dựng để ước tính cây cầu sẽ có giá bao nhiêu, vật tư cần thiết và công ty xây dựng sẽ thuê bao nhiêu công nhân. Ông ta chuyển đổi thông tin này thành các số liệu và áp dụng chúng vào mô hình đầu vào – đầu ra để tìm ba mức độ tác động.
Tác động trực tiếp chỉ đơn giản là các số ban đầu được đưa vào mô hình, ví dụ, giá trị của các yếu tố đầu vào thô (xi măng, thép, v.v.). Tác động gián tiếp là các công việc được tạo ra bởi các công ty cung ứng như công ty xi măng và thép. Tác động gây ra là số tiền mà công nhân mới chi tiêu cho hàng hóa và dịch vụ.
Như vậy ta thấy rằng vấn đề xác thực dữ liệu sớm là rất tốt và hiệu suất, nhưng xác thực dữ liệu lặp đi lặp lại là một quá trình nhàm chán và tôi thừa nhận rằng chính xác thực dữ liệu là khá khó chịu. Đó là lý do tại sao rất nhiều lập trình viên bỏ qua nó hoặc làm điều đó nửa chừng. Ngoài ra, mọi xác thực trùng lặp là một lỗi có thể xảy ra nếu chúng không được đồng bộ hóa mọi lúc. Đó là những lý do chính mà ngày nay tôi thích để hầu hết các xác nhận hợp lệ cho tầng doanh nghiệp, với chi phí thời gian, băng thông và CPU, các trường hợp ngoại lệ được xử lý theo từng trường hợp cụ thể.
3. Tại sao Dữ liệu đầu vào vô cùng quan trọng trong ngành Logistics?
Dữ liệu đầu vào được coi là nền tảng giúp cho doanh nghiệp xây dựng hệ thống vận hành dựa trên thông tin thu thập được qua thời gian. Phần lớn các công ty chỉ để cho một nhóm ít người được quyền truy cập dữ liệu đầu vào để giữ cho chúng luôn đúng và tránh sử dụng sai mục đích và dẫn đến những hậu quả không mong muốn.
Để giao dịch được thực hiện đúng cách, hệ thống phần mềm cần lưu trữ chính xác số lượng các đơn hàng và các chế độ vận chuyển. Dữ liệu lịch sử của khách hàng là rất quan trọng để giúp nhân viên kinh doanh biết các thông tin như nguồn cung hay trung tâm phân phối nào giúp giảm chi phí và tối ưu hoá quãng đường cho quá trình vận chuyển. Tất cả những dữ liệu này đều cần được lưu trữ.
Ở mặt đối lập, những dữ liệu bị sai hoặc lỗi có thể dẫn đến sai sót trong hoạt động kinh doanh. Thử tưởng tượng nếu Hệ thống quản lý vận tải (TMS) hoặc Tối ưu hoá tuyến đường (ROS) sử dụng những dữ liệu sai hoặc lỗi thời (như số lượng xe, nhà kho, người vận chuyển, tổng trọng lượng, tình trạng giao thông,…), sẽ có vô số trường hợp xấu xảy ra.
Ví dụ khi người điều phối vận tải thêm vào rất nhiều địa chỉ sai của khách hàng hoặc trọng lượng hàng hóa sai, phần mềm sẽ không thể đưa ra lộ trình chính xác hoặc tệ hơn là một lộ trình hoàn toàn sai.
Ngoài ra, việc nhập nhầm thông tin về trọng lượng còn có thể khiến hệ thống giao đơn hàng vào phương tiện không phù hợp với hàng hoá, khiến cho chi phí và thời gian tăng lên đáng kể, ảnh hưởng tiêu cực đến quan hệ với khách hàng. Do đó, tính chính xác của dữ liệu là một phần không thể thiếu trong logistics và chuỗi cung ứng. Để tránh lỗi do sử dụng dữ liệu kém chất lượng, chiến lược quản lý dữ liệu đầu vào luôn quan trọng.